Docker 입문기 1편
서론
현재 사내에서 대시 보드를 만들고 있는데 어드민, 스태프, 클라이언트 권한이 존재한다. 어느 날 해당 권한에 따라 기능 접근을 제어할 수 있었으면 좋겠다는 요구 사항이 나왔고 어드민이 스태프와 클라이언트의 권한을 제어할 수 있는 기능을 만들었다.
그러던 어느날 동일한 UI인데 백엔드 API가 권한에 따라 여러개인 상황을 만났습니다. 그래서 백엔드 API 설계를 수정 요청했으나 너무 바빠 일이 진행되지 않았다. 그래서 직접 진행해보려고 시도하면서 학습을 시작했다.
백엔드 개발자의 소스코드를 내 로컬로 가지고 와서 실행시키는 순간부터... 어려움의 연속이었다.
주말 내내 python version, DB 그리고 AWS에 동일하게 배포할 수 있는 환경을 구축했는데... 쉽지 않았다. 그래서 동료가 Docker위에 컨테이너 방식으로 배포해야한다고 했나보다를 이해했다. 내가 공부해서 도입해봐야겠다 싶어서 시작했다.
우선 Docker를 알야야 한다. 다음 동료에게 이런 시련을 줄 수 없다.
먼저는 유튜브 영상을 참고했고 인프런의 강의 (비전공자도 이해할 수 있는 Docker 입문/실전)를 2번 반복해서 익혔다. 그리고 회사 프로젝트 적용하는 과정을 진행했다. 해당 내용은 2편에 나눠 진행하려고 한다.
본론
기본 사전 지식
1. 프로세스와 프로그램
도커를 이해하는데 있어 프로세스는 상당히 중요한 개념이라 다시 정리보려고 한다. 프로그램과 프로세스는 정의된 클래스와 인스턴스 관계라고 생각할 수 있다. 나는 그렇게 이해했다. 더 나은 비유가 있다면 댓글로 알려주시면 감사하겠습니다!
// 프로그램
class Program {
constructor() {
}
static method() {
return ...
}
...
}
// 프로세스 (인스턴스)
const executedProgram = new Program();
위의 코드 처럼 나는 정의된 클래스를 Program으로 이해했고 해당 클래스를 인스턴스로 만들어 실행시킨 것을 프로세스라 이해했다.
프로세스란?
프로세스는 실행중인 프로그램을 말하며 OS 관점에서 생각해보면 관리하기 위한 단위라는 것을 명확히 알게 됐다. OS는 프로세스마다 CPU 자원과 RAM 접근 자원을 할당해준다. 널널한 개발자님의 유튜브를 통해 Task라는 개념을 알게 됐다. 프로그램을 프로세스로 바꾸는 것을 Task라고 하는데 그래서 멀티 테스킹과 같은 어휘가 있는지 알게 됐다.
실질적으로 프로세스를 아는게 도커와 무슨 상관이 있는가?
프로세스 하나를 컨테이너로 생각하면 된다. 즉 컨테이너는 곧 하나의 격리된 프로세스라고 이해하니 와닿았다. 즉 OS 입장에서 단순히 도커 컨테이너는 또 하나의 프로세스로 취급되는데 컨테이너는 과거의 vmWare과 같은 가상화 도구들에 비해 성능에 이점도 있고 독립적인 환경도 제공해준다.
정리해보면 프로세스는 실행 혹은 연산의 단위이다. OS는 단위들을 관리 및 자원 할당하는 주체이다. 그 중에서도 메모리가 엉키지 않도록 관리를 하는데. 가상 메모리 체계를 사용한다고 한다.
가상 메모리란?
가상 메모리는 다음과 같이 정의할 수 있다.
RAM, HDD 추상화하여 하나의 추상화 인터페이스 제공한 것
 출처: 다락방 블로그 이미지
출처: 다락방 블로그 이미지
프로세스를 이해해보면서 가상 메모리 체계를 사용한다는게 뭔지 궁금해졌다.
취업 면접을 준비하면서 Process에는 Stack,Heap,Code,Text 영역이 있고 Stack은 위에서 밑으로 Heap은 아래에서 위로 데이터가 추가된다는 정도로 기억하고 있는데 이번 기회에 조금 더 이해의 범위를 넓혀보려고 했다.
가상 메모리는 말 그대로,,, 눈에 보이지 않는 논리적인 메모리를 의미한다. 즉 컴퓨터의 물리적 메모리, RAM과 HDD/SSD의 주기억 장치와 보조기억 장치에 직접 추가 및 삭제하는 것이 아니라 OS가 한 단계 추상화한 메모리를 제공하는 것을 의미한다. 이로 인한 이점은 물리적인 메모리를 OS가 주체적으로 관리할 수 있게 되고 모든 PID에 따른 참조를 알고 있으니 자원을 효율적으로 관리할 수 있게 된다.
이게 지금 단계에서 내가 이해하고 있는 가상 메모리의 전부이다.
조금만 더 이해해보자, 그런데 가상 메모리는 왜 등장했을까?
우선 아주 옛날 옛적에 어플리케이션과 OS는 같은 공간에서 실행됐다고 한다. 지금은 유저 모드, 커널 모드 그리고 맨 밑에 하드웨어 단이 존재해서 각자의 역할을 수행하고 여러 프로세스를 띄우는등 우리가 알고 있는 모든 것들이 가능해진 것 같다.
아무튼 옛날에는 프로세스 하나만 띄울 수 있었고 프로세스에 많은 역할과 책임이 묶여있었다. 프로세스로 인해 하드웨어를 재부팅해야하는 경우가 잦았다고 하는데 생각해보면 어릴 적 수 없이 재부팅했던 기억이 있다. 결국 프로세스가 하드웨어를 제어하는 꼴이 되어버렸고 그래서 Intel 80286에 보호모드가 생기고 이후도 많은 것들이 바꼈다고 한다. 그래서 가상 메모리 체계로 인해 프로세스에 의존하고 있는 OS의 문제를 해결했다.
가상 메모리의 장점
- 프로세스 보호: 각 프로세스는 자신의 가상 주소 공간만 접근할 수 있어, 다른 프로세스의 메모리를 침범할 수 없습니다.
- 프로세스 자원 회수 : 프로세스가 죽었을 때, 프로세스가 사용했던 자원을 완벽하게 회수함. 그래서 실제 메모리 낭비가 일어나지 않음. 그로 인해 OS 손상 안입힘
- 메모리 효율화 : 자주 사용되지 않는 페이지는 디스크로 옮기고, 필요한 부분만 물리 메모리에 올릴 수 있습니다 (페이징 in/out Or Swap in/out).
그럼 이제 본격적인 Docker 개념 및 사용법을 알아보자
우선 도커는 왜 사용하는 건가?
핵심적으로는 이식성 때문이다.
즉 만들어놓은 프로그램을 어디에서든 실행시킬 수 있다는 것이 핵심이다. 예를 들어 현재 내 상황일 수 있다. 동료가 만들어놓은 서버 코드, 서버 코드에는 DB와, python 버전, WAS 및 Redis등 여러 디비의 버전의 패키지를 로컬에 설치해야하는데,,, 로컬에 pull 받아도 즉시 바로 실행할 수 없다. 더군다나 OS까지 다르다?? 생각보다 로컬에서 실행시키는게 번거롭게 에러가 많이 발생한다. 익숙치 않은 백엔드 코드이니 여간 답답하지 않을 수 없다.
그래서 도커가 필요하다. 설치 과정 일일이 거치지 않아도 되고 항상 일관되게 프로그램 설치 및 독립적인 환경 실행이 가능하기 때문이다.
- 이식성 (Portability): 어떤 OS든 실행 가능
- 격리성 (Isolation): 시스템 간 충돌 없이 동작
- 재현성 (Reproducibility): 모든 사람이 동일한 환경에서 개발 가능
- 자동화 용이성 (CI/CD 연계)
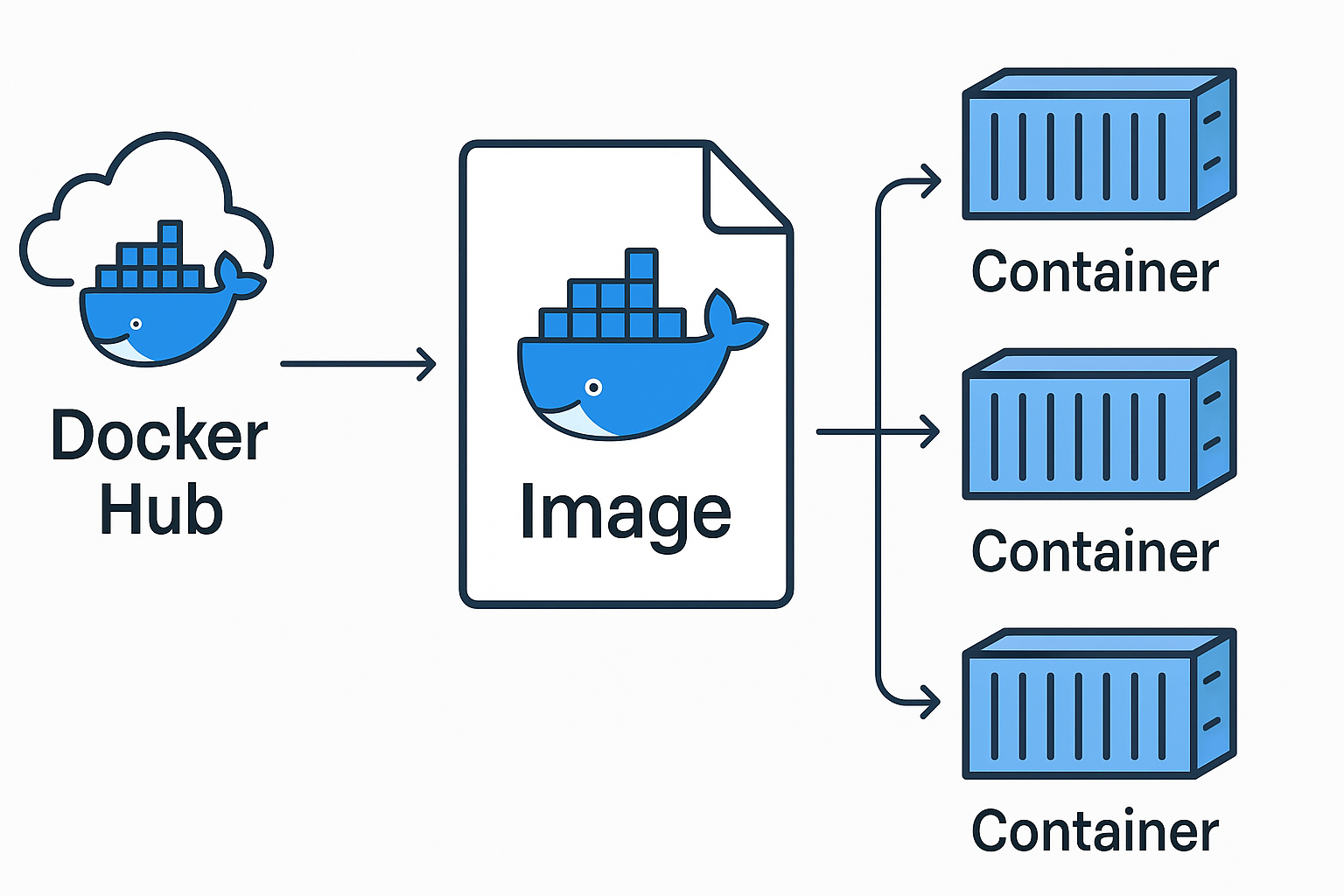
도커란?
컨테이너를 사용해서 프로그램을 분리된 환경에서 실행 및 관리할 수 있는 도구이다.
컨테이너가 무엇인가?
컨테이너는 하나의 프로세스라고 말할 수 있다. 즉 독립적인 디스크 공간과 네트워크를 가지고 있다.
그럼 이미지는 무엇인가?
컨테이너를 실행하는데 필요한 설치 및 환경 설정, 버젼등을 포함하는 것을 말한다.
상황극을 통해 도커랑 친해지기
도커를 활용해 로컬 피씨에 서버를 띄우는 상황을 가정해보았습니다.
👨💼 쿤 (선임 개발자): "이번에 우리가 쓰는 백엔드 서비스 컨테이너를 로컬에서 한번 띄워보세요. Docker Hub에 올려놓은 이미지가 있어요. 그거 pull 받아서 로컬에서 컨테이너로 실행해보고 정상적으로 API가 동작하는지 확인해주세요."
🧑💻 주영 (신입 개발자): "네! 혹시 이미지 이름하고 태그 알려주실 수 있을까요?"
👨💼 쿤 (선임 개발자): "이미지 이름은 company/backend-service:latest예요. 최신 버전으로 올려놨어요."
🧑💻 주영 (신입 개발자): "아 네. 그럼 docker pull로 먼저 받으면 되겠네요?"
👨💼 쿤 (선임 개발자): "네! 그리고 컨테이너 띄울 때는 포트 포워딩도 같이 해주세요. 예를 들어 컨테이너 안에서는 8000 포트를 쓰는데, 주영님 로컬에서는 8080으로 포워딩해서 접근할 수 있도록 해보세요"
상황극에서 신입 개발자는 도커를 알고 있어서 이미지 이름과 태그를 알려달라고 하는데... 아주 훌륭한 신입이라고 생각합니다. 여기서 이해가 되지 않아도 괜찮다. 해당 포스트를 읽고 난 후는 이해할 수 있을 것이다.
우선 이 대화를 통해 기본적인 컨테이너,이미지를 제외하고 나머지 키워드를 뽑아보면
- Docker Hub는 무엇인지
- Docker Hub에 이미지는 어떻게 만드는지
- 이미지 이름은 알겠는데 태그는 무엇인지
- 컨테이너 내부 IP와 신입 개발자 호스트 IP를 포워딩해줘야하는데 왜 그런지?
이런 궁금증이 생길 수 있을 것 같다. 아래의 과정을 살펴보고 결론에서 정리해보려고 한다.
도커 CLI 커멘트를 하나씩 이해해보자!
Docker 어플리케이션을 다운로드받으면 cli에서 사용할 수 있다.
-
docker pull nginx: Docker Hub에서 nginx:latest 이미지를 가지고 온다. tag는 :latest와 같은 것을 말하고 버전을 의미한다. 아무것도 없으면 자동으로 최신 태그의 이미지를 가지고 오게 된다. -
docker image ls: 현재 로컬에 존재하는 이미지 리스트를 확인할 수 있다. -
docker run --name web-server -d -p 80:80 nginx: 이 코드는 가지고 온 이미지를 기반으로 컨테이너를 실행하는 코드인데 자세히 보면 이름은 web-server로 한다. -d는 background로 실행하겠다는 의미이다. 즉 해당 컨테이너를 띄워놓고 다른 작업을 할 수 있도록 하기 위함이다. 그리고 -p는 포트를 매핑하는데 호스트 80번 포트와 컨테이너 80포트와 연결하겠다는 뜻이다.
- 이미지 조회/삭제
-
docker image rm [이미지 명 혹은 Image ID]: 이미지 삭제할 수 있다. 하지만 이미지를 사용 중인 컨테이너가 있다면 삭제 할 수 없기에 아래의 명령어를 사용해야 한다. -
docker image rm -f [이미지 명 혹은 Image ID]: 이미지를 삭제할 수 있다.
- 컨테이너 조회 삭제
-
docker ps: 현재 실행중인 컨테이너를 볼 수 있다. -
docker ps -a: 중지된 컨테이너를 볼 수 있다. -
docker stop webserver: 실행중인 컨테이너를 중지할 수 있습니다. -
docker rm [컨테이너명 혹은 컨테이너 ID]: 컨테이너를 삭제할 수 있다. -
docker rm $(docker ps -qa): 중지한 컨테이너 모두 삭제할 수 있다. -
docker logs [컨테이너 ID]: 컨테이너의 로그를 확인할 수 있다. -
docker logs -f: 실시간으로 로그를 볼 수 있다. -
docker exec -it [컨테이너ID] bash: 쉘로 컨테이너 내부로 진입할 수 있다.
- docker compose를 활용해서 더 쉽게 관리하는 명령어
-
docker compose ps: compose.yml 선언된 컨테이너 중 실행중인 것만 볼 수 있다. -
docker compose logs:compose.yml 선언된 컨테이너 로그를 볼 수 있다. -
docker compose up --build: 이미지 다시 빌드하고 컨테이너 실행시켜야할 때 이 명령어 사용할 수 있다. -
docker compose pull: 이미지 다운로드 받거나 업데이트할때 사용한다.
- 볼륨
docker run -v [호스트의 디렉토리 절대경로]:[컨테이너의 디렉토리 절대경로] [이미지명]:[태그명]: 호스트 컴퓨터의 절대경로와 컨테이너 디렉토리 절대 경로를 디스크를 공유하도록 지정할 수 있다.
- compose
-
docker compose ps : compose.yml 선언된 컨테이너 중 실행중인 것만 보여준다.
-
docker compse logs :compose.yml 선언된 컨테이너 로그
-
docker compose up --build : 이미지 다시 빌드하고 컨테이너 실행시켜야할 때 이 명령어 사용해야한다.
23/ docker compose pull : 이미지 다운로드 받거나 업데이트할때 사용한다.
도커 볼륨을 활용해 데이터 유실 방지
도커는 기본적으로 휘발성 컨테이너이다. 그 말인 즉슨 컨테이너가 실행되고 중단되고 재 실행될 경우 내부 데이터도 사라진다. 조금 풀어서 정리해보면 프로그램 기능 추가 되면 새로운 이미지 만들어서 컨테이너를 실행하는데 도커는 그냥 새로운 컨테이너 만들어서 통째로 갈아끼운다. 리액트의 재조정 알고리즘에도 비슷한 부분이 있는 것 같다. 리액트는 변경된 부분을 찾아 그 부분만 DOM에 교체하는데 도커는 아예 전체를 갈아끼운다는 점에서 달라보였지만 불변성과 새로운 구조를 만들어 반영한다는 것은 비슷한 점이 있다고 느꼈다.
다시 돌아와보면 이런 특성떄문에 기존 컨테이너 내부 값이 초기화된다. 디비 값이 초기화된다면 재앙인데 이런 문제를 볼륨이라는 개념을 활용하여 해결한다.
볼륨(Volume)은 컨테이너 자체의 저장 공간을 사용하지 않고, 호스트 자체의 저장 공간을 공유해서 사용하는 형태이다.
docker run -v [호스트의 디렉토리 절대경로]:[컨테이너의 디렉토리 절대경로] [이미지명]:[태그명]
이렇게 하면 내 컴퓨터 경로에 mysql 데이터 파일이 설치되고 컨테이너를 중지하고 새로운 컨테이너를 만들어고 테이블을 살펴봐도 만든 테이블이 존재하는 것을 확인할 수 있다.
Dockerfile이란?
도커 파일은 이미지를 만들어주는 파일이다. 위에서는 만들어진 이미지를 pull 받아서 가지고 온 이미지를 기반으로 컨테이너를 실행시키는 방식을 살펴보았다. 하지만 원하는 이미지가 없을 경우 혹은 커스텀한 이미지를 만들어야할 때 Dockerfile을 활용해서 이미지를 생성할 수 있다.
간단하게 fast API 활용하여 서버를 만들어보았고 이를 이미지로 만들어보았다.
FROM python:3.10
WORKDIR /code
COPY ./app /code/app
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
EXPOSE 8080
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080"]
위의 명령어는 아래에서 하나씩 살펴보겠지만 위와 같은 서버 이미지를 만들어보았다. 이렇게 이미지를 만들어 빌드해보면
$ docker build -t my-fast-api-server . # 이미지 생성
$ docker run -d my-fast-api-server # 이미지를 기반으로 컨테이너 생성
$ docker ps # 실행 중인 컨테이너 조회
$ docker exec -it [컨테이너 ID] bash # 컨테이너 접속
$ python -v # Python 설치되어 있는 지 확인
-
COPY : 파일,폴더, 특정 파일, 특정 폴더 복사가능, 특정 파일 제외 복사 가능 (.dockerignore)
-
ENTRYPOINT :컨테이너가 실행되자마자 실행시키고 싶은 명령어를 ENTRYPOINT에 작성하면 된다.
-
RUN : 이미지 생성 과정에서 명령어를 실행시켜야할 때 사용한다. run과 entrypoint 차이
run은 이미지 생성 과정에서 필요한 명령어, entrypoint는 이미지 기반 컨테이너가 실행되는 시점에 실행되는 명령어라는 것. -
WORKDIR : 지정한 디 렉터리 하위에 이쁘게 파일을 지정할 수 있다.
-
EXPOSE : 어떤 포트를 매핑했는지 알려주는 문서화의 역할을 해준다.
그런데 우리 백엔드 서버만 해도 여러 컨테이너가 존재한다. fastAPI도 있고 mysql도 있고 redis도 있는데 이런 컨테이너 일일이 docker run으로 띄우면 너무 번거롭지 않나? 그래서 docker compose를 알아보자!
Docker Compose로 복수 컨테이너 쉽게 관리하기
Docker Compose는 복수 컨테이너를 효율적으로 정의하고 운영하기 위해 만든 도구이다. 알게된 것부터 정리해보면 다음과 같다.
| 기능 | 설명 |
|---|---|
services: | 어떤 컨테이너들이 필요한지 정의 |
build: | 직접 Dockerfile로 빌드 가능 |
volumes: | 데이터 유지 |
networks: | 컨테이너 간 통신 구성 |
depends_on: | 실행 순서 지정 |
.env 파일 사용 | 민감한 설정 분리 가능 |
사용해보니 추상화가 잘 되어있다고 느꼈다. 컨테이너 실행에 있어 추상화된 명령어로 간소화할 수 있다. 이정도면 당장 실무에 적용해보고 개선할 수 있다고 느꼈다.
아주 간단한 컨테이너를 실행하는 코드를 사용해서 비교해보자!
이전에는 nginx 컨테이너를 띄우는데 아래의 명령어를 쳐야했다. 백그라운드로 실행하고 포트를 매핑해줬다.
docker run --name webserver -d -p 80:80 nginx
그런데? compose.yml 파일을 생성하면 아래와 같이 작성할 수 있다.
//compose.yml
services:
my-web-server:
container_name: web-server
image: nginx
ports:
- "80:80"
//zsh
docker compose up
너무 쉽게 된다. 그런데 포그라운드로 실행된다. 그래서 백그라운드로 실행하기 위해선 아래와 같이 작성하면 된다.
docker compose up -d
docker compose down을 하면 실행하고 있는 컨테이너를 중지해주고 삭제까지 해준다. 놀랍다.
docker compose CLI 정리해보기
- docker compose ps : compose.yml 선언된 컨테이너 중 실행중인 것만 보여준다.
- docker compse logs :compose.yml 선언된 컨테이너 로그
- docker compose up --build : 이미지 다시 빌드하고 컨테이너 실행시켜야할 때 이 명령어 사용해야함.
- docker compose pull : 이미지 다운로드 받거나 업데이트할때 사용함.
결론
도커를 공부하며 단순히 컨테이너를 띄우는 기술뿐 아니라, 프로세스, 가상 메모리, 이식성과 같은 운영체제 개념까지 함께 익힐 수 있었다. 아직 빙산의 일각이라고 느꼈지만 그럼에도 불구하고 이제 알아가볼 수 있게 됐다.
프론트엔드 개발자라 하더라도, 백엔드와의 협업 과정에서 도커를 이해하는 건 더 이상 선택이 아닌 필수처럼 느껴졌고 사내에 기여하기 위해선 직접 구축해보는게 가장 빠른 길이라고 느꼈다.
도커를 통해 기대하는 바는 “환경 설정 지옥”에서 벗어나 누구나 같은 방식으로 코드를 실행할 수 있게 된다는 것이다. 이로 인해 백엔드 소스를 클론 받고 실행하기까지 이젠 버전 충돌에 허덕이지 않게 될 것이고 Redis, DB, 백엔드 서버를 모두 한 줄로 실행할 수 있을 뿐 아니라 CI/CD 환경도 더 깔끔하게 구성하는데 필요한 기반을 다지는 시간이었다.
앞으로는 Docker 기반의 CI/CD 구성, 실전 프로젝트에 어떻게 적용했는지를 2편에서 다룰 예정이다. 현업 신입 개발자의 시행착오와 개선기를 통해, 같은 고민을 가진 분들께 조금이나마 도움이 되었으면 좋겠다.
👉 To be Continue!